As we learn how to extract energy from disordered, entropic systems such as
amorphous photovoltaics and
wind power, we can really start thinking creatively in terms of our analysis. Most of the conventional thinking goes out the window as considerations of the impact of disorder requires a different mindset.
In a recent post, I solved the Fokker-Planck diffusion/convection equation for disordered systems and demonstrated how well it applied to transport equations; I gave examples for both amorphous silicon photocurrent response and for the breakthrough curve of a solute. Both these systems feature some measurable particle, either a charged particle for a photovoltaic or a traced particle for a dispersing solute.
Similarly, the conduction of heat also follows the Fokker-Planck equation at its most elemental level. In this case, we can monitor the temperature as the heat flows from regions of high temperature to regions of low temperature. In contrast to the particle systems, we do not see a drift component. In a static medium, not abetted by currents (as an example, mobile ground water) or re-radiation, heat energy will only move around by a diffusion-like mechanism.
We can't argue that the flow of heat shows the characteristics of an entropic system -- after all temperature serves as a measure of entropy. However, the way that heat flows in a homogeneous environment suggests more order than you may realize in a practical siuation. In a perfectly uniform medium, we can propose a single diffusion coefficient,
D, to describe the flow or flux. A change of units translates this to a thermal conductivity. This value inversely relates to the
R-value that most people have familiraity with when it comes to insulation.
For particles in the steady state, we think of Fick's First Law of Diffusion. For heat conduction, the analogy is
Fourier's Law. These both rely on the concept of a concentration gradient, and functionally appear the same, only the physical dimensions of the parameters change. Adding the concept of time, you can generalize to the Fokker-Planck equation (i.e Fick's Second Law or the
Heat Equation respectively).

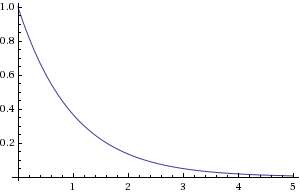
Much as with a particle system, solving the one-dimensional Fokker-Planck equation for a thermal impulse you get a Gaussian packet that widens from the origin as it diffuses outward. See the picture to the right for progressively larger values of time. The cumulative amount collected at some point,
x, away from the origin results in a sigmoid-like curve known as an
complementery error function or erfc.
Yet in practice we find that a particular medium may show a strong amount of uniformity. For example, earth may contain large rocks or pockets which can radically alter the local diffusivity. Same thing occurs with the insulation in a dwelling; doors and windows will have different thermal conductivity than the walls. The fact that reflecting barriers exist means that the
effective thermal conductivity can vary (similarly this arises in variations due to Rayleigh scattering in
wind and
wireless observations). I see nothing radical about the overall non-uniformity concept, just an acknowledgment that we will quite often see a heterogeneous environment and we should know how to deal with it.
Previously, I solved the FPE for a disordered system assuming both diffusive and drift components.
In that solution I assumed a maximum entropy (MaxEnt) distribution for mobilities and then tied diffusivity to mobility via the Einstein relation. The solution simplifies if we remove the mobility drift term and rely only on diffusivity. The cumulative impulse response to a delta-function heat energy flux stimulus then reduces to:
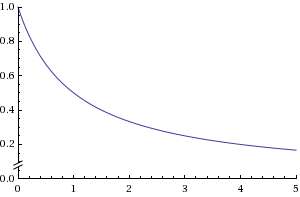
T(x,t) = T1* exp(-x/sqrt(D*t)) + T0

No
erfc in this equation (which by the way makes it useful for quick analysis). I show the difference between the two solutions in the graph to the right (for a one-dimensional distance
x=1 and a scaled diffusivity of
D=1). The uniform diffusivity form (
red curve) shows a slightly more pronounced knee as the cumulative increases than the disordered form (
blue curve) does. The fixed
D also settles to an asymptote more quickly than the MaxEnt disordered
D does, which continues to creep upward gradually. In practical terms, this says that things will heat up or slow down more gradually when a variable medium exists between yourself and the external heat source

Because of the variations in diffusivity, some of the heat will also arrive a bit more quickly than if we had a uniform diffusivity. See the figure to the right for small times. Overall the differences appear a bit subtle. This has as much to do with the fact that diffusion already implies disorder, while the MaxEnt formulation simply makes the fat-tails fatter. Again it essentially disperses the heat -- some gets to its destination faster and a sizable fraction later.

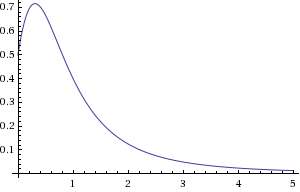
Which brings up the question of how we can get some direct evidence of this behavior from empirical data. With drift, the dispersion becomes much more obvious, as systems with uniform mobility with little disorder show very distinct knees (ala photocurrent time-of-flight measurements or solute breakthrough curves for uniform materials) . Adding the MaxEnt variation makes the fat-tail behavior very obvious, as you would observe from the anomalous transport behavior in amorphous semiconductors. With diffusion alone, the knee automatically smears, as you can see from the figure to the right for a typical thermal response measurement.
EvidenceMuch of the interesting engineering and scientific work in characterizing thermal systems comes out of Europe.
This paper investigating earth-based heat exchangers contains an interesting experiment. As a premise, they wrote the following, where incidentally they acknowledge the wide variation in thermal conductivities of soil:
The thermal properties can be estimated using available literature values, but the range of values found in literature for a specific soil type is very wide. Also, the values specific for a certain soil type need to be translated to a value that is representative of the soil profile at the location. The best method is therefore to measure directly the thermal soil properties as well as the properties of the installed heat exchanger.
This test is used to measure with high accuracy:
- The temperature response of the ground to an energy pulse, used to calculate:
- the effective thermal conductivity of the ground
- the borehole resistance, depending on factors as the backfill quality and heat exchanger construction
- The average ground temperature and temperature - depth profile.
- Pressure loss of the heat exchanger, at different flows.
The authors of this study show a measurement for the temperature response to a thermal impulse, with the results shown over the course of a couple of days. I placed a solid red and blue line indicating the fit to an entropic model of diffusivity in the figure below. The mean diffusivity comes out to
D=1.5/hr (with the red and blue curves +/- 0.1 from this value) assuming an arbitrary measurement point of one unit from the source. This fit works arguably better than a fixed diffusivity as the variable diffusivity shows a quicker rise and a more gradual asymptotic tail to match the data.

The transient thermal response tells us a lot about how fast a natural heat exchanger can react to changing conditions. One of the practical questions concerning their utility arises from how quickly the heat exchange works. Ultimately this has to do with extracting heat from a material showing a natural diffusivity and we have to learn how to deal with that law of nature. Much like we have to acknowledge the
entropic variations in wind or cope with variations in
CO2 uptake, we have to deal with the variability in the earth if we want to take advantage of our renewable geothermal resources.