You don't learn this stuff in school. They don't tell you about this in financial planning seminars. I suspect that no one really wants you to know this. I only came across it because the standard investment strategy never made sense to me. But once you understand the math you will become very wary. The trap works because most people do not understand stochastic processes and how entropy affects every aspect of our life.
What I will show is how an expected rate of return -- when not locked down -- will lead to a wild variance that in the end will only meet investors' expectation about 1/3 of the time. And the worst case occurs so routinely and turns out so sub-optimal that fat-tail probabilities essentially tell the entire story. My specific analysis provides such a simple foundation that it raises but a single confounding question:
someone must have formulated an identical argument before ... but who?The premise: To understand the argument you have to first think in terms of rates. A (non-compounded) investment rate of return,
r, becomes our variate. So far, so good. Everyone understands what this means. After
T years, given an initial investment of
I, we will get back a return of
I*T*r. In general
r can include a dividend return or a growth in principal; for this discussion, we don't care. Yet we all understand that
r can indeed change over the course of time. In engineering terms, we should apply a robustness analysis to the possible rates to see how the results would hold up. Nothing real sophisticated or new about that.
At this point let's demonstrate the visceral impact of a varying rate, which leads to a better intuition in what follows. By visceral, I mean that in certain environments we become acutely aware of how rates affect us. The value of the rate ties directly to a physical effect which in turn forms a learned
heuristic in our mind.
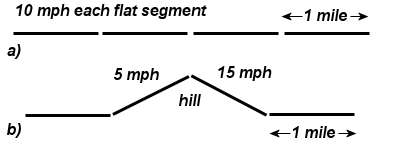
One rate example that I personally relate to contrasts riding a bike in flat versus hilly country. If I set a goal of traveling between points
A and
B in the shortest amount of time, I know from experience how the rates affect my progress. For one, I know that the hilly country would always result in the longest travel time. For the figure below, I set up an example of a
x=4 mile course consisting of four 1-mile segments. On flat ground (a) I can cover the entire course in
T=24 minutes if I maintain a constant speed of
r=10 mph (
T =
x/
r = 4/10*60).
For the hilly course (b), one segment becomes steep enough that the constant rate drops to 5 mph. Work out the example, and you will find that the time it takes to cover the course will exceed 24 minutes for any finite value of speed going down the backside of the hill. For a 15 mph downhill, the extra time amounts to 4 minutes. Only an infinite downhill speed will match the flat course in completion time. And that jives exactly with the agonizing learned behavior that comes with the physical experience.
Yet if we quickly glanced at the problem as stated we may incorrectly assume that the two hill rates average out to 10 = (5 +15)/2 and if not careful we may then incorrectly conclude that we could certainly go faster than 15 mph on the backside and actually complete the hilly course faster!
The mismatch between the obvious physical intuition we get from riding the bike course and the lack of intuition we get by looking at the abstract problem formulation extends to other domains.
This same trap exists for a rate of return investment strategy. The lifetime of an investment follows the same hilly trajectory, yet we don't experience the same visceral impact in our perception of how varying rates modify our expected rate of return. In other words, as a group of heuristically-driven humans, we have no sense of how and why we can't keep up a predictable rate of return. We also don't necessarily do a robustness analysis in our head to see how excursions in the rate will affect the result.
With that as a backdrop, let me formulate the investment problem and its set of premises. To start, assume the variation in our rate as very conservative in that we do not allow it to go negative, which would indicate that we eat away at the principal. Over the course of time, we have an idea of an average rate,
r0, but we have no idea of how much it will vary around that value. So we use the Maximum Entropy Principle to provide us an unbiased distribution around
r0, matching our uncertainty in the actual numbers.

p(r) = (1/r0) * exp(-r/r0)
This weights the rates toward lower values and
r0 essentially indicates our expectation of future payouts. Over an ensemble of
r values, the conditional probability of an initial investment matching the original principle in time
t becomes:
P(t | r0) = exp (-1/(t*r0))
Treating the set as an ensemble versus treating a single case while varying
r continuously will result in the same expression (addendum: see ref [2]). This has the correct boundary conditions: at
t=0 we have no chance of getting an immediate return, and if we wait to
t=infinity, we will definitely reach our investment goal (not considering the investment going belly-up).
This result, even though it takes but a couple of lines of derivation, has huge implications. As we really don't know the rate of return we eventually get dealt, it shouldn't really surprise us that at
T=1/
r0 the probability of achieving our expected rate of return is only
P(
t=T |
r0) = exp (-1) = 0.367.

Yet this runs counter to some of our pre-conceived notions. If someone has convinced us that we would get our principal back in
T=1/
r0 years with a certainty closer to unity (1 not 0.367), this should open our eyes a little.
(never mind the fine print in the disclaimer, as nobody really explained that either)
It boils down to the uncertainty that we have in the rate, as to whether it will go through a hilly trajectory or a flat one, generates a huge bias in favor of a long hilly latency. We just don't find this intuitively obvious when it comes to volatile investments. We continue to ride the hills, while forever thinking we pedal on flat terrain.
But it gets worse than this. For one,
r can go negative. That would certainly extend the time in meeting our goal. But consider a more subtle question: What happens if we just wait another
T=1/
r0 years? Will we get our principal back then?
According to the formula, reaching this goal becomes only slightly more likely.
P(t=2*T | r0) = exp (-1/2) = 0.606.
This continues on into fat-tail territory. Even after 10 cycles of
T, we will only
on average reach 0.9 or a 90% probability of matching our initial principal. The fat-tail becomes essentially a
1/t asymptotic climb to the expected return. This turns into a variation of the 90/10 heuristic whereby 10% of the investors absorb 90% of the hurt or 35% get 65% of the benefit. Not an overpowering rule, but small advantages can reap large rewards in any investment strategy.

Although it will never happen due to the finite limits set forth, the expected time to reach the objective logarithmically diverges to infinity. This occurs due to the 1/t^2 decay present in the probability density function (the blue single-sided
entroplet in the figure to the right). Although progressively rarer, the size of the delay compensates and pushes the expected value inexorably forward in time.
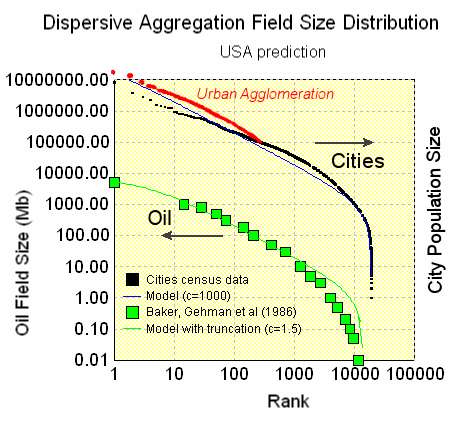
A related effect occurs in finding large oil reservoirs. We get lots of our oil from a few large reservoirs, while the investment monopoly money pays out from the fat-tail of low rate of return investments.
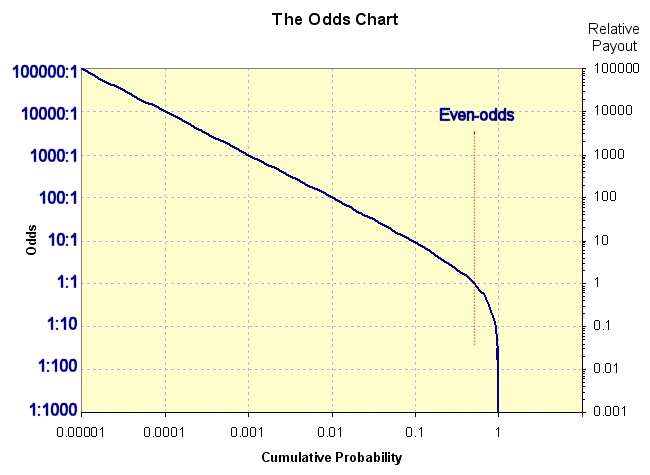
Now you can say that this really only shows the return for a hypothetical ensemble-averaged investor. We shouldn't preclude that individual investors can make money. But the individual does not concern me, as a larger filter predicts the prevailing Wall Street strategy perpetrated on the naive investor class, effectively operating under Maximum Entropy conditions. Unwittingly, the mass of investors get dragged into a Pareto Law wealth distribution, simply by making investments under a veil of uncertainty. In this situation, 37% of investors "beat the system", while 63% of the investors are losers in the sense that they don't make the expected payoff (see the adjacent figure). They contribute to the huge number of investors who only gain back a fraction of the return in the expected time. It seems reasonable that a split of 50/50 would at least place the returns in Las Vegas territory for predictability and fair play.

So who makes the money? Of course the middleman makes lots of money. So too does the insider who can reduce the uncertainty in
p(
r). And so do the investors who have fast computers who can track the rate changes quicker than others. The list of profiteers can go on.
The cold-footed investor who keeps changing his portfolio will turn out even worse-off. Each time that he misses the 37% cutoff, it makes it even more likely that he will miss it next time as well. (That happens in project scheduling as well where the
fat-tails just get fatter) The definition of insanity is "doing the same thing over and over again and expecting different results".
Putting it charitably, the elite investment community either understands the concept as subliminal tacit knowledge or have gradually adapted to it as their lifeblood. In a conspiratorial bent, you can imagine they all know that this occurs and have done a great job of hiding it. I can't say for sure as I don't even know what to call this analysis, other than a simple robustness test.
The path forward. If you look at the results and feel that this idea may have some merit, I can offer up a few pieces of advice. Don't try to win at game theoretic problems. Someone else will always end up winning the game. In my view, try to place investments into guaranteed rate of return vehicles and work for your money. A volatile investment that takes 3 times as long to reach a goal than predicted might end up providing exactly the same return as a fixed return investment ot 1/3 the interest.
On a larger scale, we could forbid investment houses to ever mention or advertise average rates of return. Simply by changing the phrase to "average time to reach 100% return on investment", we could eliminate the fat-tails from the picture. See in the graph below how the time-based cumulative exponentially closes in on an asymptote, the very definition of a "thin tail". Unfortunately, no one could reasonably estimate a good time number for most volatile investments, as that number would app
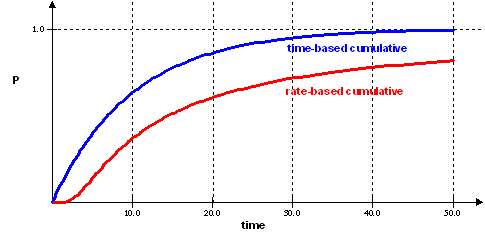
roach infinity according to maximum entropy on the rates. So no wonder we only see rates mentioned, or barring that an example of the growth of a historical investment set in today's hypothetical terms.
Briefly reflect back to the biking analogy. Take the case of a Tour de France bicycle stage through the Alps. You can estimate an average speed based on a sample, but the actual stage time for a larger sample will diverge based on the variability of rider's climbing rates. That becomes essentially the grueling game and bait/switch strategy that the investor class has placed us in. They have us thinking that we can finish the race in a timely fashion based on some unsubstantiated range in numbers. In sum, they realize the value of uncertainty.
So the only way to defeat fat-tails is to lobby to have better information available, but that works against the game theory strategies put in place by Wall Street.
So for this small window on investments, all that heavy duty quantitative analysis stuff goes out the window. It acts as a mere smokescreen for the back-room quants on Wall Street to use whatever they can to gain advantage on the mass of investors who get duped on the ensemble scale. Individual investors exist as just a bunch of gas molecules in the statistical mechanics container.
We have to watch these games diligently. The right wing of the Bush administration almost pulled off a coup when they tried to hijack social security by proposing to lock it into Wall Street investments. Based on rate of return arguments, they could have easily fooled people into believing that their rate of return didn't include the huge entropic error bars. Potentially half of the expected rate of return could have gotten sucked up into the machine.
The caveat. I have reservations in this analysis only insofar as no one else has offered it up (to the best of my knowledge). I admit that Maximum Entropy dispersion of rates generates a huge variance that we have to deal with (it definitely does not classify as Normal statistics). I puzzle why fat-tail authority and random process expert N.N. Taleb hasn't used something like this as an example in one of his probability books. I also find it worrisome that something as simple as an ordinary equity investments with strong volatility would show such strong fat-tail behavior. Everything else I had seen concerning fat-tails had only hand-wavy support.
Fat-tails work to our advantage when it comes to finding
super-giant oil reservoirs, but they don't when it comes to sociopath
etic game theory as winners do the zero-sum dance at the expense of the losers.
Or is this just evolution and adaptation taking place at a higher level than occurs for the planet's wildlife species? The winners and losers there follow the relative abundance distribution in a similar Pareto Law relationship. Each case derives completely from a
basic application of the Maximum Entropy Principle. This does seem to support the assertion that the
second law of thermodynamics has some general applicability.
Unfortunately, many mathematicians don't approve of this kind of analysis because the Maximum Entropy Principle invokes Bayesian rule and to a certain school of statisticians, Bayesian reasoning is not a formally proper approach. I suspect they would want me to start from a random walk premise and invoke a Levy flight or fractional Brownian motion. Yet it continues to explain puzzling behaviors over and over again from a practical point of view. See the
Various Consequences blog for lots of interesting discussion concerning Jaynes' ideas on how to apply Bayesian and entropy to real problems.
I am making a big leap here as I barely touch the waters of financial trading or economics[1]. In general, game theory describes economic activity, and game theory problems are
intractably difficult to solve. This may not actually constitute a real science, just psychological gamesmanship. I only worked this out to satisfy my own curiosity and would not feel bad if someone corrects me.
"In any field, the Establishment is seldom in pursuit of the truth, because it is composed of those who sincerely believe that they are already in possession of it.
-- E.T. Jaynes
---
[1] At one time I half-convinced myself that a ratchet effect took place due to the asymmetries of positive and negative stock market percentage increments. There is something odd about a 1% increase not precisely compensating a 1% decrease in the value of an investment. http://mobjectivist.blogspot.com/2006/05/taking-stock.html
[2] The rates can't swing wildly as in day-to-day market fluctuations or very fast volatility. The rates will average out normally in this case. Time has to play a factor. If the strength of an investment has a relation to the growth potential of a firm then the slow growth of a firm has to take place over a period of time. To use the hill-climbing analogy, a struggling company needs to spend extra time to climb a hill to meet its growth objectives since they have a lower effective speed. Other more capable firms can climb the hill faster so they do not spend a lot of time getting there. See a
previous post discussing scheduling bottlenecks, where we can show how companies can struggle in putting product out the door, generating very fat tails. Companies that struggle spend a longer time in the trough, so to speak. Companies that don't spend less time. So the investor gets trapped in one or the other kinds of investments, leading to a slower volatility trap.
If equity investments do not relate to the firm's long-term growth potential then we see nothing more than gaming strategies dealing with Monopoly money (i.e. pure game theory). Market rates go up and down on a whim or on the current days speculation and you can lose money off of deviations from the average only if compounding growth takes place: see volatility drag or risk drag. The fact that more people have awareness of volatility drag indicates perhaps that investors practice more speculative analysis than have concern over the "market fundamentals". No wonder we get surprised by fat-tails, as those demonstrate the real risk in investments and the frequency of slow growth.