
The Oil ConunDRUM
I synthesized the last several years of blog content and placed it into a book tentatively called The Oil ConunDRUM (ultimately titled Mathematical Geoenergy published by Wiley/AGU in 2019). This document turned into a treatise of topics relating to the role of disorder and entropy in the applied sciences. Volume 1 is mainly on the analysis of the decline in global oil production, while Volume 2 uses often related analysis in studying renewable sources of energy and how entropy plays a role in our environment and everyday life.

This is a list of the novel areas of research, listed in what I consider a ranked order of originality:
- The Oil Shock Model.
A data flow model of oil extraction and production which allows for perturbations.
- The Dispersive Discovery Model.
A probabilistic model of resource discovery which accounts for technological advancement and a finite search volume.
- The Reservoir Size Dispersive Aggregation Model.
A first-principles model that explains and describes the size distribution of oil reservoirs and fields around the world.
- Solving the Reserve Growth "enigma".
An application of dispersive discovery on a localized level which models the hyperbolic reserve growth characteristics observed.
- Shocklets.
A kernel approach to characterizing production from individual fields.
- Reserve Growth, Creaming Curve, and Size Distribution Linearization.
An obvious linearization of this family of curves, related to HL but more useful since it stems from first principles.
- The Hubbert Peak Logistic Curve explained.
The Logistic curve is trivially explained by dispersive discovery with exponential technology advancement.
- Laplace Transform Analysis of Dispersive Discovery.
Dispersion curves are solved by looking up the Laplace transform of the spatial uncertainty profile.
- The Maximum Entropy Principle and the Entropic Dispersion Framework.
The generalized math framework applied to many models of disorder, natural or man-made. Explains the origin of the entroplet.
- Gompertz Decline Model.
Exponentially increasing extraction rates lead to steep production decline.
- Anomalous Behavior in Dispersive Transport explained.
Photovoltaic (PV) material made from disordered and amorphous semiconductor material shows poor photoresponse characteristics. Solution to simple entropic dispersion relations or the more general Fokker-Planck leads to good agreement with the data over orders of magnitude in current and response times.
- Framework for understanding Breakthrough Curves and Solute Transport in Porous Materials.
The same disordered Fokker-Planck construction explains the dispersive transport of solute in groundwater or liquids flowing in porous materials.
- The Dynamics of Atmospheric CO2 buildup and extrapolation.
Used the oil shock model to convolve a fat-tailed CO2 residence time impulse response function with a fossil-fuel stimulus. This shows the long latency of CO2 buildup very straightforwardly.
- Terrain Slope Distribution Analysis.
Explanation and derivation of the topographic slope distribution across the USA. This uses mean energy and maximum entropy principle.
- Reliability Analysis and understanding the "bathtub curve".
Using a dispersion in failure rates to generate the characteristic bathtub curves of failure occurrences in parts and components.
- Wind Energy Analysis.
Universality of wind energy probability distribution by applying maximum entropy to the mean energy observed. Data from Canada and Germany.
- Dispersion Analysis of Human Transportation Statistics.
Alternate take on the empirical distribution of travel times between geographical points. This uses a maximum entropy approximation to the mean speed and mean distance across all the data points.
- The Overshoot Point (TOP) and the Oil Production Plateau.
How increases in extraction rate can maintain production levels.
- Analysis of Relative Species Abundance.
Dispersive evolution of species according to Maximum Entropy Principle leads to characteristic distribution of species abundance.
- Lake Size Distribution.
Analogous to explaining reservoir size distribution, uses similar arguments to derive the distribution of freshwater lake sizes. This provides a good feel for how often super-giant reservoirs and Great Lakes occur (by comparison)
- Labor Productivity Learning Curve Model.
A simple relative productivity model based on uncertainty of a diminishing return learning curve gradient over a large labor pool (in this case Japan).
- Project Scheduling and Bottlenecking.
Explanation of how uncertainty in meeting project deadlines or task durations caused by a spread of productivity rates leads to probabilistic schedule slips with fat-tails. Answers why projects don't complete on time.
- The Stochastic Model of Popcorn Popping.
The novel explanation of why popcorn popping follows the same bell-shaped curve of the Hubbert Peak in oil production.
- The Quandary of Infinite Reserves due to Fat-Tail Statistics.
Demonstrated that even infinite reserves can lead to limited resource production in the face of maximum extraction constraints.
- Oil Recovery Factor Model.
A model of oil recovery which takes into account reservoir size.
- Network Transit Time Statistics.
Dispersion in TCP/IP transport rates leads to the measured fat-tails in round-trip time statistics on loaded networks.
- Language Evolution Model.
Model for relative language adoption which depends on critical mass of acceptance.
- Web Link Growth Model.
Model for relative popularity of web sites which follows a diminishing return learning curve model.
- Scientific Citation Growth Model.
Same model used for explaining scientific citation indexing growth.
- Particle and Crystal Growth Statistics.
Detailed model of ice crystal size distribution in high-altitude cirrus clouds.
- Rainfall Amount Dispersion.
Explanation of rainfall variation based on dispersion in rate of cloud build-up along with dispersion in critical size.
- Earthquake Magnitude Distribution.
Distribution of earthquake magnitudes based on dispersion of energy buildup and
- Income Disparity Distribution.
Relative income distribution which includes inflection point to to compounding interest growth on investments.
- Insurance Payout Analysis, and Hyperbolic Discounting.
Fat-tail analysis of risk and estimation.
- Thermal Entropic Dispersion Analysis.
Solving the Fokker-Planck equation or Fourier's Law for thermal diffusion in a disordered environment. A subtle effect.
- GPS Acquisition Time Analysis.
Engineering analysis of GPS cold-start acquisition times.
EDIT (1/21/11): Here is a critique from TOD. I can only assume the commenter doesn't understand the concept of convolution or doesn't realize that such a useful technique exists:
Your methods are fundamentally flawed you cannot aggregate across producing basins like you do. Its simply wrong.
To add multiple producing basins together you must adjust the time variable such that all of them start production at the same time or if they have peaked all the peaks are aligned.
The time that a basin was discovered and put into production is an irrelevant random variable and has no influence on the ultimate URR.
If you don't correctly normalize the time variable across basins your work is simply garbage. There is no coupling between basins and no reason to average them based on real time. Its junk math. No simple function exists in real time to describe the aggregate production profile.
The US simply happened to have its larger basins developed about the same time in real time. Hubbert's original analysis worked simply because the error in the normalized time and real time was small.
One of the mysteries of science and mathematics is the role of entropy. The mathematician Gian-Carlo Rota from MIT had this to say just a few years ago:
 The take on this is that as Rota says about the Maximum Entropy Principle "Among all mathematical recipes, this is to the best of my knowledge the one that has found the most striking applications in engineering practice", yet it retains this sense of mystery in that no one can really prove it -- entropy just IS and by its existence, you have to deal with it the best you can.
The take on this is that as Rota says about the Maximum Entropy Principle "Among all mathematical recipes, this is to the best of my knowledge the one that has found the most striking applications in engineering practice", yet it retains this sense of mystery in that no one can really prove it -- entropy just IS and by its existence, you have to deal with it the best you can.EDIT (1/31/11): In the book, the last prediction of global crude production I made was a while ago. Here is an update:
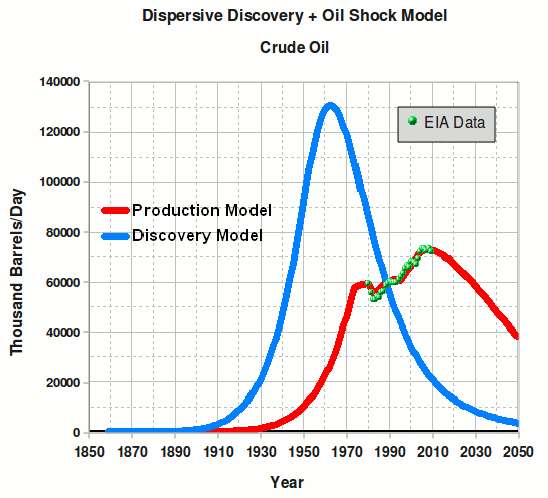
The chart above is the best guess model from 2007 using the combined Dispersive Discovery+Oil Shock Model for crude. Apart from a conversion from barrels/year to barrels/day, this is the same model as I used in a 2007 TOD post and documented in The Oil ConunDRUM. The recent data from EIA is shown as the green dots back to 1980. I always find it interesting to take the 10,000 foot view. What may look like a plateau up close, may actually be part of the curve at a distance.
EDIT (2/22/2011): An additional USA Shock Model not included in the book. I included Alaska in this model.
Discovery data transcribed from this figure; the discoveries seem to end in 1985, so I extended the data with a dispersive discovery model. I added in Alaska North Slope at 22 billion barrels in 1968 and a small 300 million barrel starter discovery in 1858.
.
 The blue line in the Dispersive Discovery Model is this equation, which is essentially a scaled version of the world model:
The blue line in the Dispersive Discovery Model is this equation, which is essentially a scaled version of the world model:DD(t)=(1-exp(-URR/(B*((t-t')^6))))*B*((t-t')^6), URR=240,000 million barrels, B=2E-7, t'=1835.
 I did not include any perturbation shocks to keep it simple. Apart from the data, the following is the entirety of the Ruby code; the discovery.txt file is yearly discovery data, which is from the first graph. The second graph shows reserve.out and production.out.
I did not include any perturbation shocks to keep it simple. Apart from the data, the following is the entirety of the Ruby code; the discovery.txt file is yearly discovery data, which is from the first graph. The second graph shows reserve.out and production.out.cat discovery.txt | ruby exp.rb 0.07 | ruby exp.rb 0.07 | ruby exp.rb 0.07 > reserve.out
cat reserve.out | ruby exp.rb 0.08 >production.out
$ cat exp.rb
def exp(a, b) rate = b length = a.length temp = 0.0 for i in 0..length do output = (a[i].to_f + temp) * rate temp = (a[i].to_f + temp) * (1.0 - rate) puts output end end exp(STDIN.readlines, ARGV[0].to_f)
posted by @whut at January 17, 2011
![]() 25 comments
25 comments
![]()














