
Double Dispersive Discovery leads to the Sigmoid and Logistic
I believe I made a significant finding in regards to the Dispersive Discovery model. In its general form, keeping search growth constant, the dispersive part of the model produces a cumulative function that looks like this:
D(x) = x * (1-exp(-k/x))dD(x)/dx = c * (1-exp(-k/x)*(1+k/x))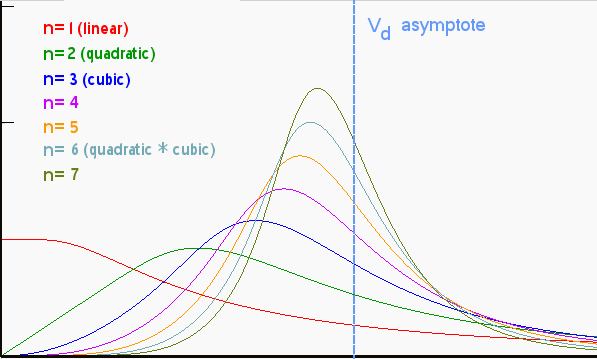
I generated this set of curves simply by applying growth terms of various powers, such as quadratic, cubic, etc, to replace x. No bones about it, I could have just as easily applied a positive exponential growth term here, and the characteristic peaked curve would result, with the strength of the peak directly related to the acceleration of the exponential growth. I noted that in an earlier post:
As for as other criticisms, I suppose one could question the actual relevance of a power-law growth as a driving function. In fact the formulation described here supports other growth laws, including monotonically increasing exponential growth.Overall, the curves have some similarity to the Logistic sigmoid curve and its derivative, traditionally used to model the Hubbert peak. Yet it doesn't match the sigmoid because the equations obviously don't match -- not surprising since my model differs in its details from the Logistic heuristics.
However, and it starts to get really interesting now, I can add another level of dispersion to my model and see what happens to the result. I originally intended for the dispersion to only apply to the variable search rates occurring over different geographic areas of the world. But I hinted that we could extend it to other stochastic variables:
We have much greater uncertainties in the stochastic variables in the oil discovery problem, ranging from the uncertainty in the spread of search volumes to the spread in the amount of people/corporations involved in the search itself.So I started with a spread in search rates given as an uncertainty in the searched volume swept, and locked down the total volume as the constant
k=L0. Look at the following figure, which show several parts of the integration, and you can see that the uncertainties only reflect in the growth rates and not in the sub-volumes, which shows up as a clamped-asymptote below the cumulative asymptote:
I figured that adding uncertainty to this term would make the result more messy than I would like to see at this expository level. But in retrospect, I should have taken the extra step as it does give a very surprising result.
That extra step involves a simple integration of the constant
k=L0 term as a stochastic variable over a damped exponential probability density function (PDF) given by p(L)=exp(-L/L0)/L0. This adds stochastic uncertainty to the total volume searched, or more precisely, uncertainty to the fixed sub-volumes searched, that when aggregated provide the total voluume.D(x) = Integral [ x * (1-exp(-L/x))*exp(-L/L0)/L0 dL ]D(x) = 1/(1/L0 + 1/x)In any case, the simple relationship that this gives, when inserted with an exponential growth term such as A*eB*t, results in the logistic sigmoid function:
D(t) = 1 / (1/L0 + 1/(A*eB*t))I will make the next statement in as passive a voice as possible. This is the Holy Grail derivation of the Logistic curve. Seriously, I don't think anyone has ever figured out how to derive the Logistic in such fundamental terms until now. The logistic has now transformed from a cheap heuristic into a model result. The fact that it builds on the Dispersive Discovery model gives us a deeper understanding of its origins. So whenever we see the logistic sigmoid used in a fit of the Hubbert curve we know that several preconditional premises must exist:
- It models a discovery profile.
- The search rates are dispersed via an exponential PDF
- The searched volume is dispersed via an exponential PDF
- The growth rate follows a positive exponential.
As a very intriguing corollary to this finding, the fact that we can use a Logistic to model discovery means that we cannot use a Logistic to model production. I have no qualms with this turn of events as production comes about as a result of applying the Oil Shock model to discoveries, and this essentially shifts the discovery curve to the right in the timeline while maintaining most of its basic shape. (And as another bit of insight, consider the application of multiple Logistic curves to model complicated scenarios. The fact that I just integrated multiple stochastic volumes over a search space to derive the logistic raises questions about the validity of such an approach. This really needs a fundamental analysis as it would necessarily duplicate the integration I have already accomplished. Unfortunately, such misuse happens when a curve gets used as a heuristic, separated from its first principles derivation.)
In spite of such a surprising revelation, we can continue to use the Dispersive Discovery in its more general form to understand a variety of parametric models, which means that we should remember that the Logistic manifests itself from a specific instantiation of dispersive discovery. Good to have this chapter closed, as the origin of the Logistic had become a nagging obsession of mine over the past few years. I can basically put it to rest, which will maintain my sanity for awhile.
As a corollary, given the result:
D(x) = 1/(1/L0 + 1/x)L0 = 1/(1/D - 1/x)
posted by @whut at June 08, 2008
![]()
![]()









4 Comments:
WHT - Nice work.
Shoot me an email at nate@theoildrum.com
Nate
Wow. Just freaking wow.
Very nice work, WHT. Now if I couple this with the significantly cruder tools that Hubbert had at the time, and I can understand why he chose to try to summarize using the Logistic, and perhaps why he settled for assuming production would follow the Logistic discovery curve. (In the US up to that time it largely had followed it.) If Hubbert had more powerful computational tools available, he might have pursued this further but lacking those he settled for what he could reasonably do.
The funny thing is, this analysis does not require any sophisticated tools. The derivation is purely analytical. Hubbert could have easily done it but he would have needed a strong background in applied probability. And it's not clear to me that someone hasn't already done this particular approach in a related field. The problem is trying to dig it up. Math like this is hard to Google.
new startup announced, google for math ... could it happen?
and, hmm, someone who actually uses a computer to compute, how amazing. remind me to poke you on facebook. via my informer/reader machine.
am so glad i am not a scientist, so much less between my mind and reality this way
enjoy, nice blog, gregory lent
Post a Comment
<< Home