
Particles on the Brain
Khebab has recently explored using the concept of Particle Filtering to estimate peak oil dynamics in a post entitled How to Track an Oil Production Curve.
It took me a while to digest this post, and I still don't have a good appreciation for the initial premise in taking this approach, but, hey, any criticism rates better than silence.
I believe Khebab wants to predict the time series continuation of current oil prediction using a resampling of historical data on top of an assumed model, choosing a Stochastic Bass Model as the underlying dynamics (which like the logistic curve, I have yet to see little intuitive physical basis for). The resampling uses Monte Carlo simulation with weighting provided by a variant of recursive Bayesian estimation, ala Kalman filtering. Now, normally I would consider using these kinds of mathematical tools if we have a signal buried in a huge amount of noise. In that sense, we get utility out of predicting future values, in a similar fashion to such real-time applications as using a phase-locked loop to demodulate a noisy FM signal. However, oil production does not suffer from noise problems per se, and in particular, the noise does not necessarily show randomness and independence from the signal itself.
Khebab initially worked with USA oil production data.
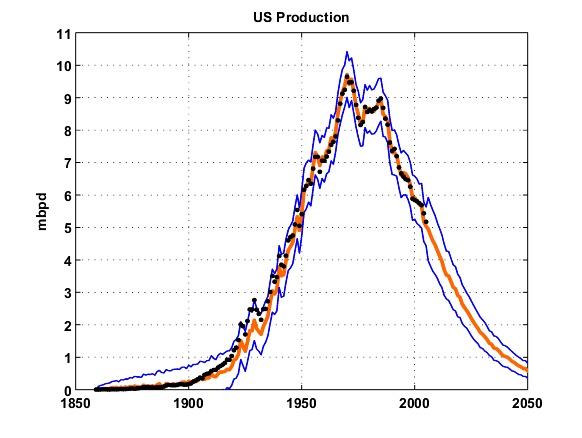
Note that the curve fits the data very accurately, but I believe this has more to do with using the data itself as a source of simulated data, i.e. the bootstrap resampling technique. This leads me to further believe that the "noise" in the production curve has virtually no impact in the simulation results. All the stochastic variation instead goes to the parameters of the model. The large total number of bootstrapped particles used to generate profile trajectories do the job of fitting in the nooks and crannies in the curve.
I find it interesting how this approach can make URR estimates out of seemingly nothing; Khebab states:
Curve fitting is a maximum likelihood approach where (sic: when?) there is no prior on the curve parameters and will produce suboptimal results when the residuals are non gaussian.Note how the PF-based Russia URR estimate totally bypasses the conventional URR straight line estimate. A distribution of priors (i.e. URR values) sampled by the Monte Carlo by itself generates the extrapolated line.

I think Khebab has made some good progress, independent on whether I have a complete grasp on what he has accomplished so far.
The particle filtering model for Russia


The oil shock model for Russia


posted by @whut at March 05, 2006
![]()
![]()









3 Comments:
Thanks for your comments. This is still a work in progress. I used a particle filtering approach mainly because I applied it on many problems in my daily work.
choosing a Stochastic Bass Model as the underlying dynamics (which like the logistic curve, I have yet to see little intuitive physical basis for).
Agreed. It could be any other model, I took this one because of its use in Marketing science and also to prove that you can gently evolve from the historical static Hubbert curve that traditional peakoilers loves so much :).
However, oil production does not suffer from noise problems per se, and in particular, the noise does not necessarily show randomness and independence from the signal itself.
It depends how you define noise. A noise is generally what is making your model/prediction different form the actual observation. The noise can also be dependent from the signal (ex: multiplicative noise).
This leads me to further believe that the "noise" in the production curve has virtually no impact in the simulation results. All the stochastic variation instead goes to the parameters of the model.
You're probably right, I'm still trying to get the right explanation myself. The main goal of a tracking method is to dynamically adapt your state parameters in order to fit the data.
Great progress, Khebab. Even though this seeems quite a difference in approach, I think there is a lot of synergy between the various models.
It will take me awhile but I think I will be able to eventually catch on to the math. I spent a bit of time studying the bootstrapping technique of Bradley Efron several years ago, so if I rack my memory banks, a lot of this stuff will start to seep back in.
Even though this seeems quite a difference in approach, I think there is a lot of synergy between the various models.
I think so too, I was planning to review your approach on GraphOilogy and make connections between the two models. I may also translate the code in R language and make it available on the website.
Post a Comment
<< Home